
第三章 进程管理
该章节主要介绍进程的相关内容。进程管理是任何操作系统的重要部分,当然也包括linux。
进程
进程在本质上就是一段程序。除了执行的代码,进程还包括一系列的资源:
- 打开的文件
- 等待的信号
- 内核数据
- 处理器状态
- 有一个或者多个内存映射的内存地址空间
- 线程
- 包含多个全局变量的数据区
执行线程
执行线程简称线程,是进程内部的活动实体。 每个线程包括:
- 程序计数器
- 线程栈
- 一系列处理器寄存器 内核调度的实体是线程,而不是进程。linux不区分进程和线程,对于linux来说,线程仅仅是一个特殊的进程。
虚拟化处理器和虚拟内存
在现代操作系统中,进程提供了两类虚拟化:虚拟化处理器和虚拟内存。
- 虚拟处理器使得进程产生独占系统的幻觉,尽管可能和其他数百个进程共享处理器。
- 虚拟内存使得进程在分配和管理内存的时候觉得自己拥有系统的全部内存。
线程共享虚拟内存抽象,然而每个线程拥有自己的虚拟处理器。
进程的生命周期
一个进程是一段运行的程序和相应资源的合体:
- 多个进程可以执行相同的程序
- 多个进程可以共享资源,比如打开的文件和地址空间
fork, exec, exit 和 wait
在linux系统中,系统调用fork()通过复制一个现有的进程而创建一个新的进程。
- 调用fork()的进程是父进程,新创建的进程是子进程。 * 父进程在创建子进程后恢复运行,同时子进程在同一个地方开始执行: fork()返回的地方。
- 系统调用fork()从内核中返回两次,一个是从父进程,一个是从子进程。
系统调用exec()创建新的地址空间,并且在fork之后装载新的程序到子进程中。在当代linux内核中,fork()实际上是通过系统调用clone()实现的,clone()会在下一节中讨论。
系统调用exit()终止当前进程并且释放其资源。父进程可以通过wait4()获取被终止的进程的状态。一个进程可以等待另一个进程的终止。当一个进程终止的时候,进程的状态会变为”僵尸”状态,该状态表示进程已经被终止,这个状态会保持直到父进程调用wait()或者waitpid()。内核实现了系统调用wait4()。linux系统通过c库提供了wait(),waitpid(),wait3()和wait4()函数。
进程描述符和进程结构
进程还有另外一个名字叫任务。linux内核将进程泛指为任务。在这本书中,进程和任务这两个概念可以交换使用,尽管在内核的观点下任务通常指进程。
内核将进程存储在一个环形的双向链表中。
进程的描述符struct task_struct(定义在<linux/sched.h>)是任务列表中的一个节点,它包含了一个进程的所有信息。
task_struct是一个比较大的数据结构,在32位的机器上大概占用1.7KB。进程描述符包含了描述运行程序的数据: 打开的文件,进程地址空间,等待的信号,进程状态等等。

分配进程描述符
task_struct是通过slab allocator(注1)分配的,这样做的好处是对象重用。结构struct thread_info进程栈的底部(栈是从高位开始朝低位增长)。

在x86系统中,结构thread_info定义在<asm/thread_info.h>中。每个任务的thread_info结构分配在栈的底部。thread_info中的task_struct指向任务的真实的task_struct。
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};
==注1: slab allocator是一种内存管理机制。可以理解为对象池。对象池中的对象可以复用,这样可以减少内存分配以及回收带来的消耗==
文件描述符的存储
process identification (PID)是一个数字(使用pid_t表示),用于区分进程。默认的最大值是32768(short int),尽管该值可以增长到4000000万(在<linux/threads.h>中控制)。内核在文件描述符中存储pid。
大型的服务器可能需要超过32768个进程。越大值表示该进程是最近才启动的(原文 The lower the value, the sooner the values will wrap around, destroying the useful notion that higher values indicate later-run processes than lower values)。管理员可以通过修改 /proc/sys/kernel/pid_max来增长最大值。
在内核中,每个进程都可以直接通过一个指针指向task_struct。实际上,内核代码直接通过struct task_struct处理进程工作。所以,能够快速的查找到进程的描述符是很有用的,而查找是通过一个叫做current的宏来完成的。这个宏必须根据不同的体系结构提供不同的实现:
- 在某些体系结构中保存指向
task_struct的指针在寄存器中 - 另一些体系结构比如x86(没有过多的寄存器)通过计算
thread_info存储在内核栈的位置,然后查找task_struct。
在x86结构中,current通过将栈指针的后13位置为0获得thread_info所在位置。这个是在current_thread_info中实现的,汇编代码如下所示:
movl $-8192, %ea
andl %esp, %eax
上面的代码是在栈大小为8KB的前提下。当4K栈启动的时候,上面的8192会被替换为4096。current通过引用thread_info来返回task_sturct。
current_thread_info()->task;
进程状态
进程描述符中的state描述了进程当前的运行情况。

系统中的每个进程都处于上面五个状态中的一个。状态通过五个标志来表示:
- TASK_RUNNING: 进程可运行状态;进程可能处于运行状态,也可能在可运行队列中等待调度。只有当进程处于这个状态的时候,进程才有可能在用户空间运行; 同时也在内核空间表示进程在运行状态。
- TASK_INTERRUPTIBLE: 进程处于睡眠状态(阻塞),等待某些条件出现。如果进程进程接收到信号,进程也可能提前被唤醒,变成可运行状态。
- TASK_UNINTERRUPTIBLE: 这个状态和TASK_INTERRUPTIBLE基本上一样,不同的是它不能接收信号而提前被唤醒。这个状态适用于进程必须等待某些事件发生并且不能被中断的情况,或者事件很快就会发生的情况。因为在该状态下进程不会响应信号,所以相比于TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE被使用的频率不是那么高。
- __TASK_TRACED: 当前进程被其他进程跟踪,比如通过ptrace实现的debugger
- __TASK_STOPPED: 进程被终止。进程既不处于运行状态,也没有资格被调度。当进程接收到信号SIGSTOP, SIGTSTP, SIGTTIN或者SIGTTOU,或者进程处于debugged的时候接收到任何信号,进程都会转变为__TASK_STOPPED。
操作进程状态
内核代码经常需要改变进程状态。进程的改变通过下面的方式实现:
set_task_state(task, state); /* set task ‘task’ to state ‘state’ */
这个函数将进程设置为特定的状态。在某些场景下,该方法使用内存栅栏(memoryy barrier)保证其他处理器的有序执行(仅在SMP系统)。因此该方法实际上等同于,
task->state = state;
方法set_current_state(state)等于set_task_state(current, state)。可以再<linux/sched.h>中看到这些方法的实现
进程上下文
进程运行的代码来自可执行文件,并且运行在进程的地址空间中。
- User-space(用户空间): 通常情况下进程运行在用户空间。
- Kernel-space(内核空间): 当进程执行系统调用或者触发了异常的时候,进程会进入到内核空间。在这时候,内核代表当前进程运行(executing on behalf of the process),同时处于进程的上下文中。只要在进程的上下文中,
current宏就能正常工作。
除了进程上下文,还有中断上下文。在中断上下文时,系统不代表进程运行,而是处于中断处理。中断处理不和任何进程绑定。退出内核后,进程继续在用户看空间运行,除非在间歇期有更高优先级的进程出现,进程调度器会选择那个更高优先级的进程运行而不是当前进程。
进程只能通过下面的接口进入到内核空间:
- 系统调用
- 异常处理
进程树(The process family tree)
系统中所有的进程都是init进程的后代。内核在启动过程的最后一步启动init进程。init进程读取系统初始化脚本,并且执行更多的程序,最终完成系统的启动。
- 系统中的每一个进程都会有父进程。
- 每个进程都会有0个或者更多的子进程。
- 拥有相同父进程的进程被称为兄弟进程(siblings)。
list_head中的next和prev存储了其他list_head中的地址。具体的结构可以参照下图:
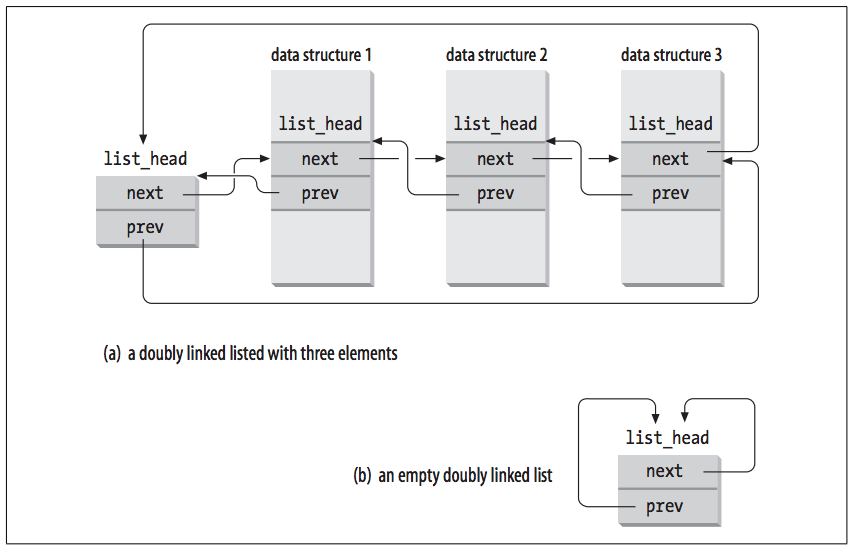
进程之间的关系存储在进程描述符中。每个task_struct(include/linux/sched.h#L1170)都含有:
- parent: 指向父进程的task_struct
- children: 指向子进程列表(struct list_head)
可以通过如下的方式获取父进程的描述符:
struct task_struct *my_parent = current->parent;
可以通过如下方式遍历进程的所有子进程:
struct task_struct *task;
struct list_head *list;
list_for_each(list, ¤t->children) {
task = list_entry(list, struct task_struct, sibling);
/* task now points to one of current's children */
}
- list_for_each: include/linux/list.h#L367
init进程的描述符存放在全局的init_task中,下面的代码通常可以执行成功:
struct task_struct *task;
for (task = current; task != &init_task; task = task->parent)
;
/* task now points to init */
你可以根据进程的层级关系从一个进程跟踪到另一个进程。你可以很轻松的遍历所有进程,这是因为系统的进程列表是循环的双向链表。 获取链表中的下一个进程,可以通过下面的代码实现:
list_entry(task->tasks.next, struct task_struct, tasks)
获取链表中的前一个进程,可以通过如下的代码实现:
list_entry(task->tasks.prev, struct task_struct, tasks)
- list_entry: include/linux/list.h
上面的两段代码在内核中有对应的宏,分别是next_task(task)和prev_task(task)。
宏for_each_process(task)可以遍历进程列表,每次循环task指向列表中的下一个进程:
struct task_struct *task;
for_each_process(task) {
/* this pointlessly prints the name and PID of each task */
printk("%s[%d]\n", task->comm, task->pid);
}
- for_each_process: include/linux/sched.h#L2139
当系统中有很多进程的饿时候,遍历每个进程的操作是很昂贵的,在这么做之前你需要三思。
进程创建
大多数操作系统实现spawn机制,在新的地址空间来创建进程,读取可运行程序。unix系统将这几步分为两个方法: fork()和exec()。
fork(): 通过复制当前进程创建新的进程。只有PID、PPID(父进程pid)和某些不继承的资源与父进程不一样。exec(): 装载一个新的程序到地址空间,并且开始执行。
Copy-on-Write
如果fork()复制父进程的所有资源到子进程,这是低效的,这是因为父子进程可能共享这些资源。更糟糕的是,子进程可能会立刻执行新的程序(通过exec加载),之前的所有拷贝内容都浪费了。
在linux中,fork()通过copy-on-write实现。
Copy-on-write(COW)可以延迟或者不复制数据。相比于复制进程的地址空间,父进程和子进程共享一个拷贝。
如果某个数据被修改,那么这个数据将会被标记,然后父子进程各自有自己的一个拷贝。资源的复制只会在资源被修改的时候才会发生,直到修改发生之前这些资源都是只读的。
如果某些页从来不会被改写,那么它们也就不会被拷贝。
fork()唯一的开销就是页表的拷贝和子进程描述符的创建。通常情况下,如果进程在fork()之后立刻执行新的程序,那么copy-on-write可以节省大量的资源拷贝带来的开销。这是一个很重要的优化,因为unix哲学鼓励进快速启动。
Forking
linux通过clone()实现fork(),clone()接受一系列的标志用于指定哪些资源需要被父子进程共享。
fork(),vfork()和__clone都是调用clone(),并且指定各自所需的标志位clone()调用do_fork()
fork中的大部分工作是在do_fork()中完成的,do_fork()定义在<kernal/fork.c>中。do_fork()调用copy_process()方法,然后运行新的进程。
- do_fork(): kernel/fork.c#L1354
- copy_process(): kernel/fork.c#L957
fork中最有趣的一部分在copy_process()中:
- 它调用
dup_task_struct()创建子进程的描述符,同时设置以下的属性和父进程一致: * 内核栈 * thread_info * task_struct - 检查当前进程没有超过当前用户的可启动进程限制。
- 一些属性被清除或者初始化,用于区分父子进程: * 不需要从父进程继承的属性主要包括一些统计信息 * task_struct的大多数属性仍然保持不变
- 进程状态设置为TASK_UNINTERRUPTIBLE,保证当前进程还未开始运行
- 调用
copy_flags()更新task_struct中的标志信息(per process flags: include/linux/sched.h#L1693) * PF_SUPERPRIV表示当前进程是否需要超级用户权限,这个标志位被清除 * PF_FORKNOEXEC表示当前进程还没有执行exec(),这个标志位被设置 - 调用alloc_pid给子进程分配pid
- 根据传入到clone的标志位,
copy_process()复制或者共享下面的资源: * Open files(打开的文件) * Filesystem information(文件系统信息) * Signal handlers(信号处理) * Process address space(进程空间) * Namespace(命名空间) - copy_process()返回一个指向当前进程的指针
回到do_fork()方法,如果copy_process()成功返回,新进程被唤醒并且执行。
内核会先运行子进程。如果内核先执行父进程,那么当子进程在启动后立刻执行exec方法的时候,父进程修改数据后copy-on-write带来的拷贝就会变得无效了(注1)。
==注2: 在这种情况下copy-on-write带来的拷贝对于子进程是没有意义的,因为子进程执行了exec方法,exec会覆盖子进程里面原有的数据==
vfork()
vfork() 方法和fork()方法的效果一致,除了页表不进行复制。子进程作为父进程地址空间内的唯一线程运行,并且父进程会阻塞,直到子进程调用exec() 或者退出。子进程不允许对地址空间进行修改。
如今,再有了copy-on-write和子进程优先运行的语义下,vfork()带来的唯一好处是不拷贝父进程的页表。
vfork() 也是通过调用clone()实现的,它传入了特殊的标志:
- 在copy_process中,task_struct中的vfork_done被设置为NULL。
- 在
do_fork()中,如果特殊的标志位被设置,vfork_done指向一个特殊的地址。 - 当子进程运行后,父进程等待子进程发送信号给它。信号的发送是通过vfork_done指针完成的。
- 在
mm_release()方法中,vfork_done会被检查是否为NULL。如果不是,父进程会被发送信号。 - 回到
do_fork()方法,父进程唤醒并且返回。
如果上面的几步都顺利执行,那么子进程会在新的地址空间运行,并且父进程回到原来的地址空间继续执行。开销是很低的,但是实现不够优雅。
==注3: 子进程只有调用exec,父进程才能继续执行?==
linux线程的实现
- 线程是一种编程抽象,多个线程共享同一个地址空间。
- 线程也可以共享打开的文件和其他资源。
- 在多核系统上,多线程可以用于并发编程,并且在这种情况下并发编程也可以叫做并行编程。
linux对于线程有自己独特的实现:
- 对于linux内核来说,不存在线程的概念。Linux通过标准的进程来模拟线程的实现。
- linux对于线程没有提供特殊的调度方式,也没有提供特殊的数据结构来表示线程。相反,一个线程仅仅是和其他进程共享特定资源的进程。
- 每个线程都有自己的task_struct,对于内核来说就是一个普通的进程。线程仅仅是共享资源,比如地址空间。
这种实现方式和其他操作系统比如windows、sun solaris完全不同,这些操作系统原生支持了线程。
创建线程
线程的创建和普通进程一样,需要传递特殊的标志位用于共享特定的资源:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
上面的代码和fork()基本一致,除了设置了标志CLONE_VM,CLONE_FS, CLONE_FILES和CLONE_SIGHAND。 而fork()则是通过下面的代码实现的,
clone(SIGCHLD, 0);
vfork()则是通过下面的代码实现的,
clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0);
上面提到的标志位,在<linux/sched.h>(include/linux/sched.h#L5)中定义的,这些标志位用于指定子进程和父进程之间共享哪些资源。
Flag Meaning
CLONE_FILES Parent and child share open files.
CLONE_FS Parent and child share filesystem information.
CLONE_IDLETASK Set PID to zero (used only by the idle tasks).
CLONE_NEWNS Create a new namespace for the child.
CLONE_PARENT Child is to have same parent as its parent.
CLONE_PTRACE Continue tracing child.
CLONE_SETTID Write the TID back to user-space.
CLONE_SETTLS Create a new TLS (thread-local storage) for the child.
CLONE_SIGHAND Parent and child share signal handlers and blocked signals.
CLONE_SYSVSEM Parent and child share System V SEM_UNDO semantics.
CLONE_THREAD Parent and child are in the same thread group.
CLONE_VFORK vfork() was used and the parent will sleep until the child wakes it.
CLONE_UNTRACED Do not let the tracing process force CLONE_PTRACE on the child.
CLONE_STOP Start process in the TASK_STOPPED state.
CLONE_CHILD_CLEARTID Clear the TID in the child.
CLONE_CHILD_SETTID Set the TID in the child.
CLONE_PARENT_SETTID Set the TID in the parent.
CLONE_VM Parent and child share address space.
内核线程
内核线程是在内核空间中的进程,它们用于内核在后台执行某些特定的操作。 和普通线程的不同:
- 内核线程没有地址空间。它们的mm指针为NULL。
- 内核线程只能运行在内核空间,不会切换上下文到用户空间。
和普通线程相似的地方:
- 内核线程是可调度的并且是可抢占的。
linux系统会把某些任务交给内核线程,比如flush线程和ksoftirqd。使用ps -ef可以看到这些内核线程。
内核线程是在系统启动的时候启动的。一个内核线程只能被另一个内核线程启动。内核通过fork kthreadd进程来自动启动这些内核线程。
内核线程相关的接口定义在<linux/kthread.h>(include/linux/kthread.h)中,
kthread_create() 启动一个新的内核线程,
struct task_struct *kthread_create(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)
新的进程是通过clone()创建的,
- 新的进程会执行threadfn函数,这个函数被当做参数传入kthread_create
- 进程的名字是namefmt
- 该进程被创建后处于非运行状态,直到调用
wake_Up_process()之后才能够运行。
通过函数kthread_run(),进程可以被创建并且运行:
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)
这个方法kthread_run(), 实际上是一个宏,
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *k; \
\
k = kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(k)) \
wake_up_process(k); \
k; \
})
内核线程创建后会一直运行知道它调用do_exit()或者内核其他部分执行kthread_stop(),在调用kthread_stop()的时候传入kthread_create()返回的task_struct:
int kthread_stop(struct task_struct *k)
进程终止
当进程终止的时候,内核释放进程拥有的资源并且通知该进程的父进程。
当进程调用exit()方法的时候会终止自己:
- 明确的: 进程调用系统调用
exit() - 隐晦的: 进程从main函数返回的时候。C编译器会在main的最后添加
exit()
当进程接收到一个它不能处理或者忽略的信号或者异常的时候,进程会被动终止。
无论进程以何种方式被终止,最后都需要调用do_exit(),do_exit()定义在kernel/exit.c(kernel/exit.c)中。do_exit()做了如下的工作:
- 设置task_struct的PF_EXITING标志位
- 调用
del_timer_sync()方法移除所有内核计时器。当del_timer_sync()返回的时候保证没有计时器正在运行,并且没有计时器在排队。 - 如果BSD的进程统计功能开启,
do_exit()调用acct_update_integrals()将统计信息回写 - 调用
exit_mm()方法释放该进程的mm_struct,如果没有其他进程在使用这个进程空间,内核会释放空间 - 调用
exit_sem()。如果进程在等待某个IPC semaphore,它会退出等待队列 - 调用
exit_files()和exit_fs()来减少文件句柄和文件系统的引用。 - 设置进程的退出码,这个退出码存放在task_struct的exit_code中,父进程可以选择性的获取该退出码。(It sets the task’s exit code (stored in the exit_code member of the task_struct) to that provided by exit() or whatever kernel mechanism forced the termination. The exit code is stored here for optional retrieval by the parent.)
- 发送信号给父进程,并且通知子进程寻找新的父进程
* 调用
exit_notify()发送信号给进程的父进程 * 将同线程组的线程或者init进程指定为其子进程的新的父进程 * 设置task_struct中的exit_state为EXIT_ZOMBIE - 调用
schedule()切换到新的进程 * 因为当前进程处于不可调度状态,所以这会是当前进程执行的最后的代码。do_exit()没有返回。
到这里:
- 所有和该进程相关的对象已经释放
- 该进程不可运行,并且状态是EXIT_ZOMBIE
- 目前其拥有的唯一内存是内核栈,thread_info和task_struct结构
- 该进程仍然存在用于提供信息给其父进程。当父进程提取信息后,或者通知内核其不感兴趣,该进程剩余的内存就会被释放。
移除进程描述符
当do_exit()完成后,进程描述符仍然存在,但是进程处于僵尸状态不能运行。
进程的清除工作和移除其描述符分开的步骤。这样做可以使得系统可以在进程终止后获取信息。
在遇到下面的情况后,终止进程的task_struct会回收利用:
- 父进程从被终止的进程的获取信息
- 父进程通知系统它不关注被终止的进程
wait() 方法通过系统调用wait4()来实现。
通常情况下调用wait()的方法后进程会被挂起直到其中的一个子进程退出,此时wait()返回退出进程的pid。
release_task() 用于释放进程描述符:
- 调用
__exit_signal(),__exit_signal()调用__unhash_process()方法,__unhash_process()最后调用detach_pid()把进程从pidhash移除,并且从任务列表中删除。 __exit_signal()释放进程的其他所有剩余资源- 如果线程是线程组的最后一个线程,并且leader的状态是zombie,
release_task()通知僵尸进程的父进程 release_task()调用put_task_struct()来释放进程内核栈中的页,和thread_info以及task_struct中的slab缓存
The Dilemma of the Parentless Task
如果父进程比子进程先退出,子进程必须寻找一个新的进程作为其父进程。否则没有父进程的被终止进程将会一直保持僵尸状态,浪费系统的内存。
为了防止无父进程的子进程被终止的时候一直处于僵尸状态,需要从线程组或者init进程中寻找一个新的父进程。
do_exit() 调用exit_notify(),exit_notify()调用forget_original_parent(),forget_original_parent()调用find_new_reaper()来寻找新的父类:
static struct task_struct *find_new_reaper(struct task_struct *father)
{
struct pid_namespace *pid_ns = task_active_pid_ns(father);
struct task_struct *thread;
thread = father;
while_each_thread(father, thread) {
if (thread->flags & PF_EXITING)
continue;
if (unlikely(pid_ns->child_reaper == father))
pid_ns->child_reaper = thread;
return thread;
}
if (unlikely(pid_ns->child_reaper == father)) {
write_unlock_irq(&tasklist_lock);
if (unlikely(pid_ns == &init_pid_ns))
panic("Attempted to kill init!");
zap_pid_ns_processes(pid_ns);
write_lock_irq(&tasklist_lock);
/*
* We can not clear ->child_reaper or leave it alone.
* There may by stealth EXIT_DEAD tasks on ->children,
* forget_original_parent() must move them somewhere.
*/
pid_ns->child_reaper = init_pid_ns.child_reaper;
}
return pid_ns->child_reaper;
}
上面的代码试图在进程的线程组中查找一个进程。如果线程组中没有对应的进程,那么返回init进程。
在合适的父进程找到后,每个子进程需要重新指定父进程。
reaper = find_new_reaper(father);
list_for_each_entry_safe(p, n, &father->children, sibling) {
p->real_parent = reaper;
if (p->parent == father) {
BUG_ON(p->ptrace);
p->parent = p->real_parent;
}
reparent_thread(p, father);
}
```c
void exit_ptrace(struct task_struct *tracer)
{
struct task_struct *p, *n;
LIST_HEAD(ptrace_dead);
write_lock_irq(&tasklist_lock);
list_for_each_entry_safe(p, n, &tracer->ptraced, ptrace_entry) {
if (__ptrace_detach(tracer, p))
list_add(&p->ptrace_entry, &ptrace_dead);
}
write_unlock_irq(&tasklist_lock);
BUG_ON(!list_empty(&tracer->ptraced));
list_for_each_entry_safe(p, n, &ptrace_dead, ptrace_entry) {
list_del_init(&p->ptrace_entry);
release_task(p);
}
}
当一个进程被ptraced后,调试进程会临时成为被ptraced进程的父进程。当一个进程的父进程终止的时候,它和它的兄弟进程必须重新寻找父进程。在之前的内核中,这会导致系统遍历所有进程来寻找兄弟进程。解决方法是单独为进程存储一份列表,列表中存放ptraced继承,这样用于减少寻找子进程的开销。
当所有进程重新找到父节点后,就不存在进程一直处于僵尸状态而无法回收的危险了。init进程针对其子进程调用wait()方法,清除僵尸进程。
原文地址: https://notes.shichao.io/lkd/ch3/